Introduction
Modern Cloud ERP solutions are increasingly adopting microservices and enabling interaction with their core systems via API calls, making integration with external systems that include AI services, email, office products more seamless than ever. In this article, we deep dive into how a “Request to Order” (a subset of CRM ERP process) can be systematically automated using AI/ML guided by good Agile principles. A reference architecture using various AI/ML services in Azure Cloud and ERP solutions provided by Microsoft Dynamics 365 are discussed.
Data Science and ERP
Data Scientists in most enterprises are several hops away from real business functions. Traditionally, ETL engineers pump the data from front end ERP/PoS systems to traditional Data Warehouses or Hadoop Data lakes. It’s only after the data finally arrives in the Data lake that the Data Scientists first lay their eyes on the data. But unfortunately, each hop adds to delay, loss in data fidelity and most importantly, loss of business context.
For instance, at DIVERGENCE.ai, just bypassing the Hadoop/Teradata/Vertica systems and directly connecting Spark to cloud/SQL store read replicas knocked off nearly 6 weeks off model development and deployment cycle at our Fortune 500 clent. Why such dramatic result? Because we only imported the data that proved to be useful in increasing ROI instead of blindly ingesting data without knowing which data will be useful. Additionally, exploring how the source systems were organized, working with ERP/CRM professionals in the front lines proved extremely valuable in understanding the underlying business processes.
Our objective as Data Science and Management Consultants is to move our teams closer to real problems. ERP(CRM/Operations/Finance etc) is where real business happens, regardless of whether we’re solving problems centered around Marketing, Operational Excellence, Fraud and Food Safety. The closer we get to these systems, the professionals and customers who rely on these systems, the better we understand the underlying processes that run a company, and the better we’ll be able to assist to analyze and solve problem using the best in class AI/ML algorithms.
Moreover, tagged and curated data is the most valuable asset for any organization. Without tagging the data to some extent, ML/AI algorithms cannot be trained to fit your specific business needs. And what better people to tag an enterprise’s data than the folks directly working in the front lines, or even better, your customers! For example when an employee in the Order Processing Department moves a Request for Quote (RFQ) email to a folder/tag named “Potential Opportunity”, that is the most accurate tagging possible! It is done by the professional in the trenches who knows the job best! Tag enough of these emails and an algorithm that can classify emails and extract the metadata from the RFQ to match your company’s offering is not that far off.
The Business Case
Pack’n Fresh is a rapidly growing food contract packer. As their company grows, they want to improve their communication between CRM, Finance and Operations. One major pain point revolves around keeping track of emails. Several emails come to the same inbox. Below are some typical email categories
- Request for Quote (RFQ) from potential customers.
- Intent: Does the request match our offering. If yes, forward to Sales.
- Challenges:
- Different RFQ formats from various prospects
- Mapping RFQ to Company’s Product Offering and resources
- Calculating internal cost and pricing
- Tracking profitability of first job and refining future quotes
- RFQs from pre-existing customers with established contracts
- Intent: Create a Quote and convert to Order quickly to service the customer in time
- Challenges
- Fluctuations in prices (Eg: Produce)
- Number of suppliers, quantity they can provide at any given time
- Differences in prices among these suppliers
- Company’s own inventory in-house, inventory in-flight etc to make sure they can meet delivery deadlines
Note that Pack’n Fresh packages and delivers perishable produce, so their RFQ to delivery is typically 2-10 days.
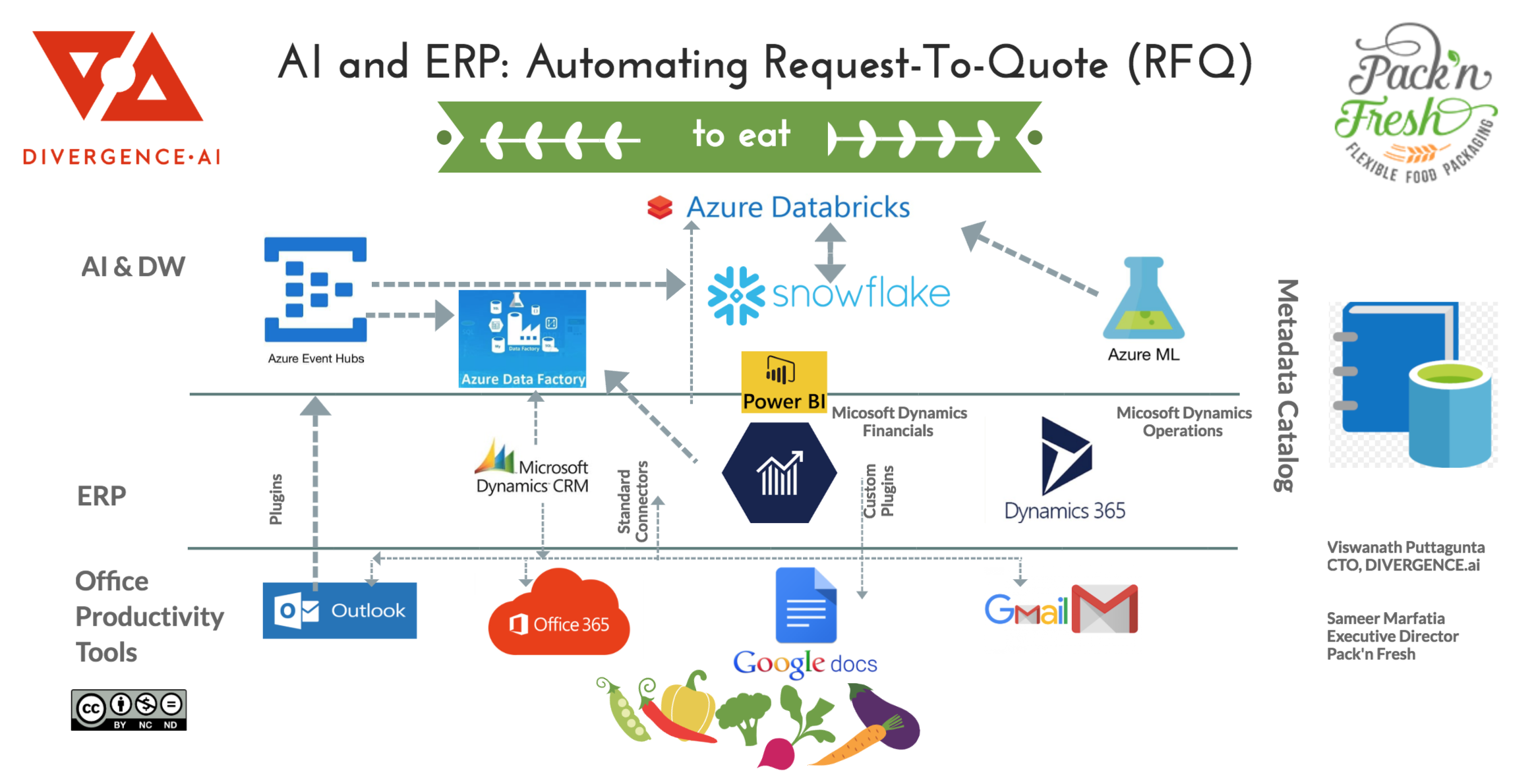
Reference Architecture
Phase 1 (Typically 16-20 weeks)
Be very skeptical of solutions that claim 100% automation in first try with AI. Instead setup a robust workflow using combination of invaluable human workforce and cloud/serverless technologies early on to tag and annotate the data without disrupting existing workflows. Leverage default plugins available and build custom plugins as needed into the email, CRM, Finance and Operations modules.
Regardless of complexity, focus on what can be done in 16-20 weeks fully deployed in the field to get first hand feedback from customers. The logistics of deploying ML/AI at scale tends to be more complex than the individual algorithms themselves. Even a 4-5% improvement is significant in this cycle as it assures that the Data Science and Engineering teams actually comprehended the business case and are solving the right problem.
Automate tasks that are relatively simple to automate first. In the above example, classifying the email based on text and metadata in attachments is relatively easier compared to understand intent in a prospective customers RFQ. Note that extracting metadata from attachments might need to be done manually at least during the initial phases as the email format and attachments could be in very diverse formats. Despite many claims, this remains a very challenging problem until we have very good annotated data.
Curate the pricing from various vendors, potentially coming from emails, shared google spreadsheets, vendor quotes etc and feed into cloud data warehouse.
Most importantly, as you build your intelligence, catalog the metadata so that we can find the data when we need most.
Technologies best suited for above tasks (available in Azure)
- Dynamics 365 CRM
- ERP for Sales Automation and Customer Service
- Dynamics 365 Finance and Operations
- in our scenario, for getting (and setting) pricing information
- Azure Databricks
- enables collaborative data analysis and model building (at scale) across Business, Operations, IT and Data Science teams.
- Track your Metadata Catalog with auto-tagging and peer review
- Flexible schema stores to save the annotated/other data
- Azure Cosmos DB: Best for saving annotation data key-value pairs for each document/email.
- Snowflake DB on Azure: Generic data warehouse rebuilt for cloud.
- Gluent | Transparent Data Virtualization to Eliminate Data Silos
- Do not replicate data if at all possible. If you must, however, at least automate it.
- Plugins for Outlook Email to extract the email and attachment content
- API for Dynamics 365 Business Central
- https://docs.microsoft.com/en-us/dynamics-nav/fin-graph/
- APIs to ERP systems usually based on https://www.odata.org/
- Serverless API applications to pump the data to Azure cloud
- https://azure.microsoft.com/en-us/overview/serverless-computing/
- Azure Queue Service
- SendGrind (Similar to AWS Simple Email Service)
- Annotation and Computer Vision services to extract metadata from Image PDFs.
- Text based classification
- Python-Pandas-sklearn, NLTK, Naive-Bayes
- Understanding key words specific to your domain is crucial before you apply advanced techniques.
Phase 2 (Typically 8-12 week iterations)
Continue to improve automation rates as you have more annotated data for email classification. Start to use “Intent” techniques to better understand whether the RFQ is in line with company’s offering.
For pre-existing customers with signed contracts, work on generating pricing and auto generate quotes. At all times, make sure to have reliable human checks and make it easy for field staff to better annotate the data and provide feedback.
Aggregate data from vendors, external sources to set the right pricing for the current bid. Again, prioritize simple and statistical/fourier time series techniques (frequency analysis / arima) before you delve into deep learning based pricing techniques. Statistical and Fourier Time series techniques can be explained very well to Business stakeholders to get their feedback. Never underestimate the gut feeling of the business stakeholders. They typically have decades of experience in the field and the models in their brain are extremely effective during feature selection process. Rely on them heavily for domain knowledge.
Before increasing the complexity of your ML/AI model, make sure your existing model output is seamlessly plugged into the Financial/Vendor/Item Pricing ERP system and measure the impact of your baseline model to top/bottom line.
Use pre built models productized by Azure/AWS/Google especially for vision and text before you try to build your own models.
Technologies best suited for above tasks (available in Azure)
- Time Series Forecasting
- ARIMA based forecasting
- Fourier based Time Series analysis
- Beware of Deep Learning LSTM based Time Series models. They are not very interpretable, so if the Data Scientist doesn’t have extensive domain knowledge, this can be disastrous.
- Advanced Text based Classification, Syntax Parsers and intent extractors
- Advanced Object Detection (Custom)
Phase 3 and beyond
Use the Phase 1 and Phase 2 output to see where to improve. For example, lot of intelligence put into predicting pricing and demand can be reused to predict dynamic human resource needs. A good strategy is to attack an adjacent problem and see how intelligence can be reused.
Hiring considerations to do Data Science projects
By the time you read this article, some of the services will become obsolete and new techniques and technologies will take their place. Hire a team that is grounded in basics and is nimble to learn and apply at scale. Hiring based on a specific tool or technique is a sure way to fail.
About the Authors
Viswanath Puttagunta
As the CTO and Principal Data Scientists at DIVERGENCE.ai, Vish helps companies incubate Data Driven teams centered around Marketing, Operational Excellence, Fraud Detection and Food Safety.
As the Director of Data Science Programs at Divergence Academy, he teaches and continuously evolves the curriculum for Data Science on Big Data/Cloud based on feedback from various consulting engagements and market research.
Sam Marfatia
Sam is the managing director at SatVida Capital. An experienced marketing & product management executive with a proven record in building products, services and business and scaling them to more than $100m in annual revenue.
Sam is the co-founder and executive director at Pack’n Fresh
About the Companies
Divergence.AI is a Full service Management and AI consulting firm. We are based in Dallas, TX.
Our deep capabilities in strategy, process, analytics and technology help our clients improve their performance. We provide expert, objective advice to help solve complex business and technology challenges. We bring our knowledge and experience to develop and integrate AI-driven solutions within the customer’s business environments.
Pack’n Fresh
Pack’n Fresh specializes in packing pre-portioned dry food ingredients primarily serving the meal-kit delivery industry. SQF Level 2 Certified and FSMA Compliant. Multiple state-of-the-art packaging machinery including VFFS, HFFS, Flow Wrap, Rotary. Various pouch materials and designs: Stand-up, Pillow, Gusset, Block-Bottom, etc. Product we pack and distribute include grains, nuts, dried fruit, breads, dry pasta, flour, spices, etc.
Additional References
Dynamics 365 (CRM, NAV, AX) Overview Training: (Source: udemy.com)
Dynamics 365 Finance and Operations Architecture (Source: docs.microsoft.com)
Gluent | Transparent Data Virtualization to Eliminate Data Silos