
The Data Scientist in me wants to learn every algorithm out there.
The Engineer in me craves to dive deep into every use case and the engineering tools they used to stitch the solution together and make it robust.
But as a CTO, while I do think it is vital to deep dive on demand, I find it more important to focus on the methodologies, provide our teams with a general framework within which we evolve and make sure it is inline with the vision and principles set by our CEO.
Every day is a delicate dance between a new gizmo I want to learn to use and developing the framework we want to empower our team with.
I see a reflection of the conflict within, in most IT organizations we work with.
Should IT have a dedicated Data Science and Machine Learning team and take on projects funded by various Business Units?
Or should they empower Business units with a robust platform and empower them to dig into the Data and come up with AI models themselves?
The right strategy in my opinion is a combination of the two, with a heavy bias towards empowering the Business.
I was at the Databricks Spark AI summit last week. With over 4000 attendees, it’s an amazing place to get a sense of the direction the AI industry is heading. Reducing friction to empower Business, and building AI systems that improve Human Experience (not just robotic automation) are the big themes that resonated across various talks.
- Empowering Business
The talk given by the IT infrastructure team at Starbucks captured the very essence of the summit.
“You Build It. You Own It” was the slogan their IT infrastructure team came up with.
Self Serve analytics does not mean clicking buttons without having to write any code. It is about systematically eliminating the friction between domain knowledge (Business Units) and Data (IT), with minimal code.
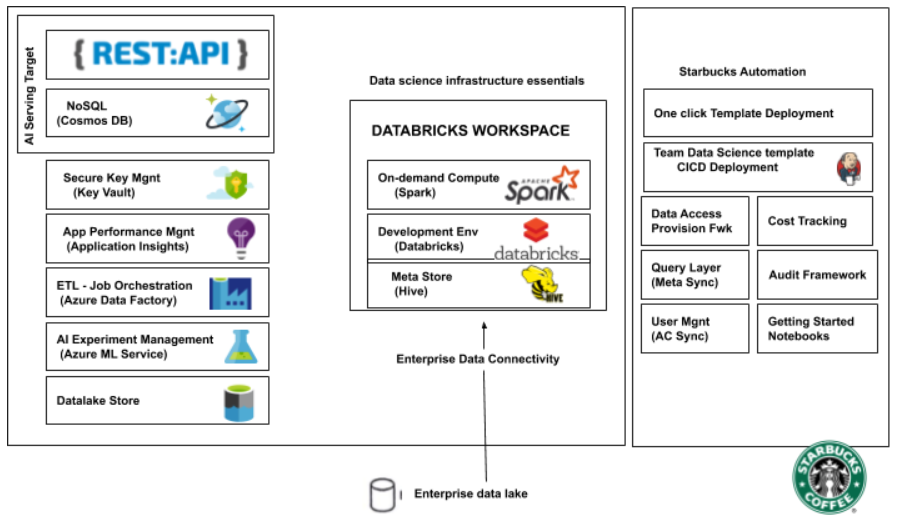
Note: Slide Reproduced from Spark AI Summit Talk from Starbucks IT & Infrastructure Team
What the folks in the BrewKit team at Starbucks came up with is a way to do just that. You have Business Units like Marketing, Operations and Finance on one side and Data and IT on the other. Here’s how their internal BrewKit platform works:
Let’s say you’re the Marketing team. To measure the impact of various campaigns across various channels, you need access to data across all these channels to begin with. The data may be stored across various data systems. You go fill out a simple form, and within 40 minutes, your Marketing team gets a Playground, a Databricks Spark Cluster with all the necessary data sets mounted to the cluster. Everyone in your marketing team now has read access to the data they need. The team manager gets a Power BI dashboard that is able to monitor the usage of the cluster to make sure the team is within Budget as well as who’s using the compute power and data. The Business Analysts and Data Scientists in the Marketing team can now spend weeks exploring the data and coming up with AI models without bothering IT.
The idea above is not entirely new. Some tools claim to do this already. But what impressed me the most is how much the Starbucks IT infrastructure team took this idea to heart and explained their journey. It was about systematically reducing friction between Business and Data. Reducing the lead time from 6-9 months, to now just under 40 mins! I’m sure there is friction still, the systems might not be perfect. But there is definitely steady progress. It’s the spirit of the people using the tool that matters more than the tool.
Reducing friction between Business and IT is also heavily dependent on the maturity of the tools. When I was at AT&T back in 2016, we wanted to bring the Business Analysts close to the on-prem Hadoop system. The out of box experience for a Business Analyst, who had a lot of domain knowledge, comfortable with Visualizations Tools like Power BI/Tableau and coding skills in SQL and basic Python was just terrible. Even Jupyter Notebook support was extremely limited due to Enterprise security reasons. Pandas support was not out of the box. R support except in vendor’s marketing material was a joke. Installing any libraries that did not come preinstalled was an admin’s nightmare. Hive performance was terrible and took 20 – 40 minutes to run most queries as it did neither had a Spark backend nor any caching layer.
When we introduced Databricks on Azure to one of our clients last October, who are on an on-prem Hadoop instance, it was an eye opener. After a few weeks of training, for the first time, I saw even managers and directors (not just the super technical folks) across IT and Business kick off a cluster and work on a Notebook and interactively build a basic model within a few hours! They were discussing and arguing about on real data! Not some silly powerpoint slide!
What was still a challenge at the time was teaching them PySpark after starting them with Python Pandas. They were still new to AI. Learning Python and Pandas was the first hurdle to overcome for many analysts. Even more difficult was to learn how to frame Business problems in a way AI can solve and how to plan for uncertainty. Introducing Spark API when they were trying to internalize this knowledge, was too much to ask, given the time constraints.

With the introduction of Koalas library[1] by Databricks (open source BTW!), effort is well underway to merge Spark and Pandas libraries. Python Pandas is the gateway into Data Science for me and millions like me. Any step that enables us to model at enterprise scale without having to learn 5 languages and 10 tools is a step in the right direction.
Delta [2] was another big announcement that is relevant in this context, a feature that greatly improves Data quality by enforcing schema on top of Parquet files and adds better governance with time travel capability. From a business perspective, less code (again.. not NO code) for streaming as well as batch pipelines.
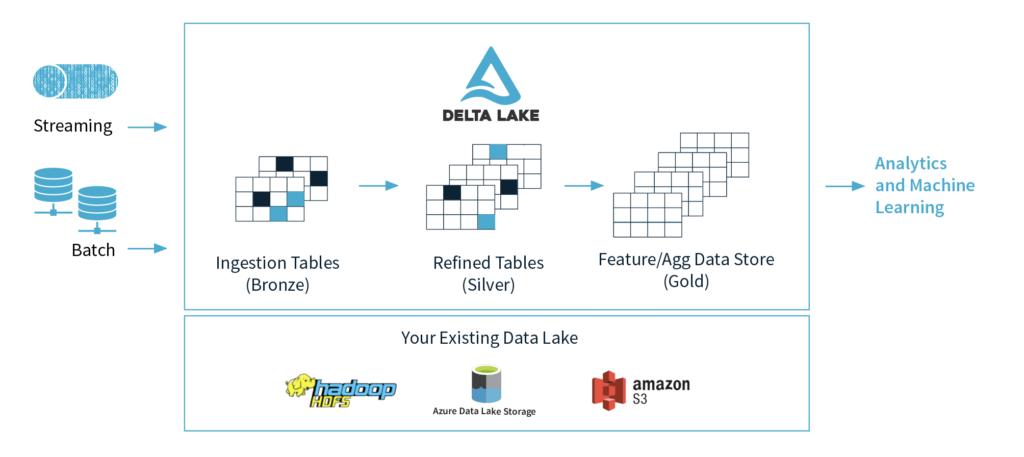
Image Courtesy: https://databricks.com/product/databricks-delta
- Improving Human Experience
Another talk that captivated me the most was from Dr. Michael Jordan [3], Professor of EECS at UC Berkeley on his keynote on “Principles of Human Centered AI”. Thinking of AI to be used for mere automation will not improve Human Happiness.
For example, most recommenders work one way. For instance, a Yelp recommends restaurants to you. This practice in general creates monopolies where very few people benefit too much with scraps for the rest. Recommenders instead should be among multiple agents. For example, restaurants should be able to bid on customers based on their interests and what restaurants can offer. This kind of real time bidding / recommenders across agents will empower the gig economy, thus enhancing human experience.
Similar key note by Caitlin Smallwood from Netflix also had a similar theme on how they use AI to bridge the gap between Content Producers and Content consumers.
Summary
- Empower Business by reducing friction between their domain experience and the data.
- Get AI models into production instead of being content with how fancy the algorithm sounds.
- Strive to empower every human with AI instead of merely focusing on automation.
About DIVERGENCE.ai
Divergence.AI is a Full service Management and AI consulting firm. We are based in Dallas, TX.
Our deep capabilities in strategy, process, analytics and technology enable us to help our clients improve their performance. We provide expert, objective advice to help solve complex business and technology challenges. We bring our knowledge and experience to develop and integrate AI-driven solutions within the customer’s business environments. DIVERGENCE.ai is a Microsoft Partner in Data & Analytics speciality.
About the Author: Vish Puttagunta
As the CTO and Principal Data Scientists at DIVERGENCE.ai, Vish helps companies incubate Data Driven teams centered around Marketing, Operational Excellence and Fraud Detection.
As the Director of Data Science Programs at Divergence Academy, he teaches and continuously evolves the curriculum for Data Science on Big Data/Cloud based on feedback from various consulting engagements and market research.
References
[1] https://databricks.com/blog/2019/04/24/koalas-easy-transition-from-pandas-to-apache-spark.html
[2] https://databricks.com/product/databricks-delta
[3] https://databricks.com/session/keynote-from-michael-i-jordan